It’s been a little while since I’ve written anything; I’ve just gotten bogged down in actually doing work. That is what happens when you start a new job and go to a new client. There are a few things I'd like to discuss.
First, I would like to congratulate Tracy McMullen from interRel on becoming an Oracle Ace Director. It requires a lot of work and she deserves it. For those of you who don’t know, There are two types of Oracle Aces. The standard Ace and Ace Directors. Oracle Aces are nominated for their work helping others and willingness to share their knowledge. Oracle Ace Directors are those people who go beyond what an Ace does and truly evangelize Oracle products. Being an Ace director also requires additional work doing presentations, attending events and many more things. While you don’t have to do much as an ACE, you have to commit time (actually sign an agreement) to what you will do as a Director. Tracy jumped over the Oracle Ace level and was honored as an Ace Director for all of her past and future work. I’m sure Tracy is up to the challenge, so I am glad she was bestowed this honor.
Second, I’ve been on the committee putting together the ODTUG Kaleidoscope conference this year. It will be bigger and better than last year. In addition to Essbase topics, we will have sessions on other Hyperion applications, reporting tool and even hands on labs for things like Essbase Studio, OBIEE+ and Java. While there might be changes(standard disclaimer) you can see the schedule on Tim Tow’s Essbase Blog http://timtows-hyperion-blog.blogspot.com/2008/12/tentative-odtug-hyperion-schedule.html If you attend no other conference this year, be sure to attend this one. It is completely technical in nature and you are constantly learning. I learned a lot last year and expect to get a lot out of this year’s conference as well. It's much cheaper than training classes and you learn so much more than the basics you get from a class.
Third, when I started my blog this last spring, there were not a lot of other blogs out there dealing with Essbase topics, but I’ve been looking around the web community and am amazed at the number of new Essbase related blogs that have popped up. There are a lot of people putting out quality information. I’ve read about ODI, OBIEE, EPM Fusion Edition 11.1.1 (.1), tuning tips, MDX formulas and so much more. There are a few links to other blogs here on my site, and each of these blogs has links to other great blogs. Spend a few minutes and you’ll be amazed at how much you can find.
Now onto some more technical stuff. I recently have been working with a couple of other skilled consultants and we were running into a problem with a dimension build (Parent/Child) coming out very funky. At first we were doing it from SQL and it seemed to work fine, but when we BCP’ed the dimension data to a flat file and tried to run it, we got the outline not building the dimension properly. It took a while to figure it out. Turns out the alias column for one member had nothing but a space in it. This caused problems. In our case it was easy to change the view we were pulling from to substitute the member name where the alias was a space, but it was odd that from SQL it was ok and from a flat file it wasn’t. As another workaround, I guess in the rules file we could have replaced space with a character selecting all occurrences, then replace the character with nothing matching whole word only and finally replacing the character with a space for all occurrences. It sounds like a lot of work sometimes is necessary. A similar thing can be done to replace a null column with a default value.

 You can have a whole set of report scripts connected to buttons, click on the button and it clears the retrieval sheet, sets the appropriate report script range to the retrieval range and does the retrieval. You now have an almost instant reporting system.
You can have a whole set of report scripts connected to buttons, click on the button and it clears the retrieval sheet, sets the appropriate report script range to the retrieval range and does the retrieval. You now have an almost instant reporting system. Talking about asymmetrical reports, here is where some settings make a difference. From the Tech reference “ [< Asym] prints an asymmetric report (with BLOCKHEADERS) only when all column dimensions include the same number of selected members and all members from each column dimension are on the same line. Otherwise, a symmetric report (with PYRAMIDHEADERS) is produced.” What does this mean? Well if I have the columns of time and scenario and I want Actuals for Jan and Budget for Feb and Mar, let’s see what different options give us. If I do a symmetrical report like:
Talking about asymmetrical reports, here is where some settings make a difference. From the Tech reference “ [< Asym] prints an asymmetric report (with BLOCKHEADERS) only when all column dimensions include the same number of selected members and all members from each column dimension are on the same line. Otherwise, a symmetric report (with PYRAMIDHEADERS) is produced.” What does this mean? Well if I have the columns of time and scenario and I want Actuals for Jan and Budget for Feb and Mar, let’s see what different options give us. If I do a symmetrical report like: I’ll get a report that looks like the following.
I’ll get a report that looks like the following. You will see that I get Jan having Actual and Budget and Feb having Actual and budget. Each month has the same number of items under it. If I change the Sym to Asym to turn it into the following asymmetrical report .
You will see that I get Jan having Actual and Budget and Feb having Actual and budget. Each month has the same number of items under it. If I change the Sym to Asym to turn it into the following asymmetrical report . I get a different report where Jan is only for Actual and Feb only for Budget.
I get a different report where Jan is only for Actual and Feb only for Budget. Just like in the first example, if I do a symmetrical report of three month and Actual and budget.
Just like in the first example, if I do a symmetrical report of three month and Actual and budget. I get the report shown below:
I get the report shown below: But If I try to change it to an asymmetrical report
But If I try to change it to an asymmetrical report I get the following error
I get the following error This is because I have to have an equal number of members for both dimensions otherwise the report generator does not know how to process it. A simple change
This is because I have to have an equal number of members for both dimensions otherwise the report generator does not know how to process it. A simple change I’ve said report scripts can be faster than excel retrievals. Here is a good example. Suppose I want to get a member of the product dimension and its attributes. I could set up a sheet like:
I’ve said report scripts can be faster than excel retrievals. Here is a good example. Suppose I want to get a member of the product dimension and its attributes. I could set up a sheet like: Zoom in on the different attributes (turning on suppress missing). In an Excel add-hoc retrieval, it is a slow process - zooming in on each of the attributes. To switch to another product, I have to start all over. An easier solution is to set up a report script like:
Zoom in on the different attributes (turning on suppress missing). In an Excel add-hoc retrieval, it is a slow process - zooming in on each of the attributes. To switch to another product, I have to start all over. An easier solution is to set up a report script like: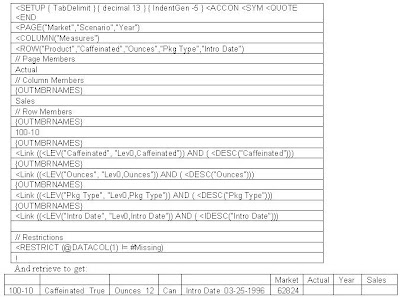 When I want to change product, I simply replace the product and retrieve again. I have a cube with 16 attributes and can get the attributes for a product almost immediately. I then use them in a dashboard report. If I try to do this with zooming in, it’s a bunch of code and much slower. In one case the difference was sub-second vs. 10 minutes.
When I want to change product, I simply replace the product and retrieve again. I have a cube with 16 attributes and can get the attributes for a product almost immediately. I then use them in a dashboard report. If I try to do this with zooming in, it’s a bunch of code and much slower. In one case the difference was sub-second vs. 10 minutes.



The EDM AI Change Assistant: What It Is and Why It Matters
-
This will be a three part series covering the EDM Change Management
Assistant. I was able to see a demo of this in action and it really changed
my opinion ...
2 days ago

